Advanced: Pipelines#
Pipelines often interact with external resources like Hadoop/Spark clusters or data warehouses like Snowflake or BigQuery. Dagster provides various facilities to avoid hard-coding interactions with such systems, so that your business logic can remain the same across different environments (local/test, dev, prod, etc.) Resources represent these external systems, and modes/presets support swapping resource implementations across different environments.
Parametrizing Pipelines with Resources#
Dagster models interactions with features of the external environment as resources.
Dagster's library modules such as dagster_aws,
dagster_gcp, and
dagster_slack provide out-of-the-box implementations for
many common external services.
Typically, your data processing pipelines will want to store their results in a data warehouse somewhere separate from the raw data sources. We'll adjust our toy pipeline so that it does a little more work on our cereal dataset, stores the finished product in a swappable data warehouse, and lets the team know when we're finished.
You might have noticed that our cereal dataset isn't normalized—that is, the serving sizes for some cereals are as small as a quarter of a cup, and for others are as large as a cup and a half. This grossly understates the nutritional difference between our different cereals.
Let's transform our dataset and then store it in a normalized table in the warehouse:
@solid(required_resource_keys={"warehouse"})
def normalize_calories(context, cereals):
columns_to_normalize = [
"calories",
"protein",
"fat",
"sodium",
"fiber",
"carbo",
"sugars",
"potass",
"vitamins",
"weight",
]
quantities = [cereal["cups"] for cereal in cereals]
reweights = [1.0 / float(quantity) for quantity in quantities]
normalized_cereals = deepcopy(cereals)
for idx in range(len(normalized_cereals)):
cereal = normalized_cereals[idx]
for column in columns_to_normalize:
cereal[column] = float(cereal[column]) * reweights[idx]
context.resources.warehouse.update_normalized_cereals(normalized_cereals)
Resources are another facility that Dagster makes available on the context object passed to solid
logic. Note that we've completely encapsulated access to the database behind the call to
context.resources.warehouse.update_normalized_cereals. This means that we can easily swap resource
implementations—for instance, to test against a local SQLite database instead of a production
Snowflake database; to abstract software changes, such as swapping raw SQL for SQLAlchemy; or to
accommodate changes in business logic, like moving from an overwriting scheme to append-only,
date-partitioned tables.
To implement a resource and specify its config schema, we use the @resource decorator. The decorated function should return
whatever object you wish to make available under the specific resource's slot in
context.resources. Resource constructor functions have access to their own context argument,
which gives access to resource-specific config. (Unlike the contexts we've seen so far, which are
instances of SystemComputeExecutionContext, this context is
an instance of InitResourceContext.)
class LocalSQLiteWarehouse:
def __init__(self, conn_str):
self._conn_str = conn_str
# In practice, you'll probably want to write more generic, reusable logic on your resources
# than this tutorial example
def update_normalized_cereals(self, records):
conn = sqlite3.connect(self._conn_str)
curs = conn.cursor()
try:
curs.execute("DROP TABLE IF EXISTS normalized_cereals")
curs.execute(
"""CREATE TABLE IF NOT EXISTS normalized_cereals
(name text, mfr text, type text, calories real,
protein real, fat real, sodium real, fiber real,
carbo real, sugars real, potass real, vitamins real,
shelf real, weight real, cups real, rating real)"""
)
curs.executemany(
"""INSERT INTO normalized_cereals VALUES
(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)""",
[tuple(record.values()) for record in records],
)
finally:
curs.close()
@resource(config_schema={"conn_str": Field(String)})
def local_sqlite_warehouse_resource(context):
return LocalSQLiteWarehouse(context.resource_config["conn_str"])
The last thing we need to do is to attach the resource to our pipeline, so that it's properly
initialized when the pipeline run begins and made available to our solid logic as
context.resources.warehouse.
@pipeline(
mode_defs=[
ModeDefinition(
resource_defs={"warehouse": local_sqlite_warehouse_resource}
)
]
)
def resources_pipeline():
normalize_calories(read_csv())
All resources are associated with a ModeDefinition So far,
all of our pipelines have had only a single, system default mode, so we haven't had to tell Dagster
what mode to run them in. Even in this case, where we provide a single anonymous mode to
the @pipeline decorator,
we won't have to specify which mode to use (it will take the place of the default mode).
We can put it all together with the following config:
resources:
warehouse:
config:
conn_str: ":memory:"
solids:
read_csv:
inputs:
csv_path:
value: "cereal.csv"
Here we pass the special string ":memory:" in config as the connection string for our
database—this is how SQLite designates an in-memory database.
Expressing Resource Dependencies#
We've provided a warehouse resource to our pipeline, but we're still manually managing our
pipeline's dependency on this resource. Dagster also provides a way for solids to advertise their
resource requirements, to make it easier to keep track of which resources need to be provided for a
pipeline.
@solid(required_resource_keys={"warehouse"})
def normalize_calories(context, cereals):
columns_to_normalize = [
"calories",
"protein",
"fat",
"sodium",
"fiber",
"carbo",
"sugars",
"potass",
"vitamins",
"weight",
]
quantities = [cereal["cups"] for cereal in cereals]
reweights = [1.0 / float(quantity) for quantity in quantities]
normalized_cereals = deepcopy(cereals)
for idx in range(len(normalized_cereals)):
cereal = normalized_cereals[idx]
for column in columns_to_normalize:
cereal[column] = float(cereal[column]) * reweights[idx]
context.resources.warehouse.update_normalized_cereals(normalized_cereals)
Now, the Dagster machinery knows that this solid requires a resource called warehouse to be
present on its mode definitions, and will complain if that resource is not present.
Pipeline Modes#
By attaching different sets of resources with the same APIs to different modes, we can support running pipelines—with unchanged business logic—in different environments. You might have a "unittest" mode that runs against an in-memory SQLite database, a "dev" mode that runs against Postgres, and a "prod" mode that runs against Snowflake.
Separating the resource definition from the business logic makes pipelines testable. As long as the APIs of the resources agree, and the fundamental operations they expose are tested in each environment, we can test business logic independent of environments that may be very costly or difficult to test against.
class SqlAlchemyPostgresWarehouse:
def __init__(self, conn_str):
self._conn_str = conn_str
self._engine = sqlalchemy.create_engine(self._conn_str)
def update_normalized_cereals(self, records):
Base.metadata.bind = self._engine
Base.metadata.drop_all(self._engine)
Base.metadata.create_all(self._engine)
NormalizedCereal.__table__.insert().execute(records)
Even if you're not familiar with SQLAlchemy, it's enough to note that this is a very different
implementation of the warehouse resource. To make this implementation available to Dagster, we
attach it to a ModeDefinition.
@pipeline(
mode_defs=[
ModeDefinition(
name="unittest",
resource_defs={"warehouse": local_sqlite_warehouse_resource},
),
ModeDefinition(
name="dev",
resource_defs={
"warehouse": sqlalchemy_postgres_warehouse_resource
},
),
]
)
def modes_pipeline():
normalize_calories(read_csv())
Each of the ways we can invoke a Dagster pipeline lets us select which mode we'd like to run it in.
From the command line, we can set -d or --mode and select the name of the mode:
dagster pipeline execute -f modes.py -e resources.yaml -d unittest
Or, from the Python API:
run_config = {
"solids": {
"read_csv": {"inputs": {"csv_path": {"value": "cereal.csv"}}}
},
"resources": {"warehouse": {"config": {"conn_str": ":memory:"}}},
}
result = execute_pipeline(
pipeline=modes_pipeline,
mode="unittest",
run_config=run_config,
)
And in Dagit, we can use the "Mode" selector to pick the mode in which we'd like to execute.
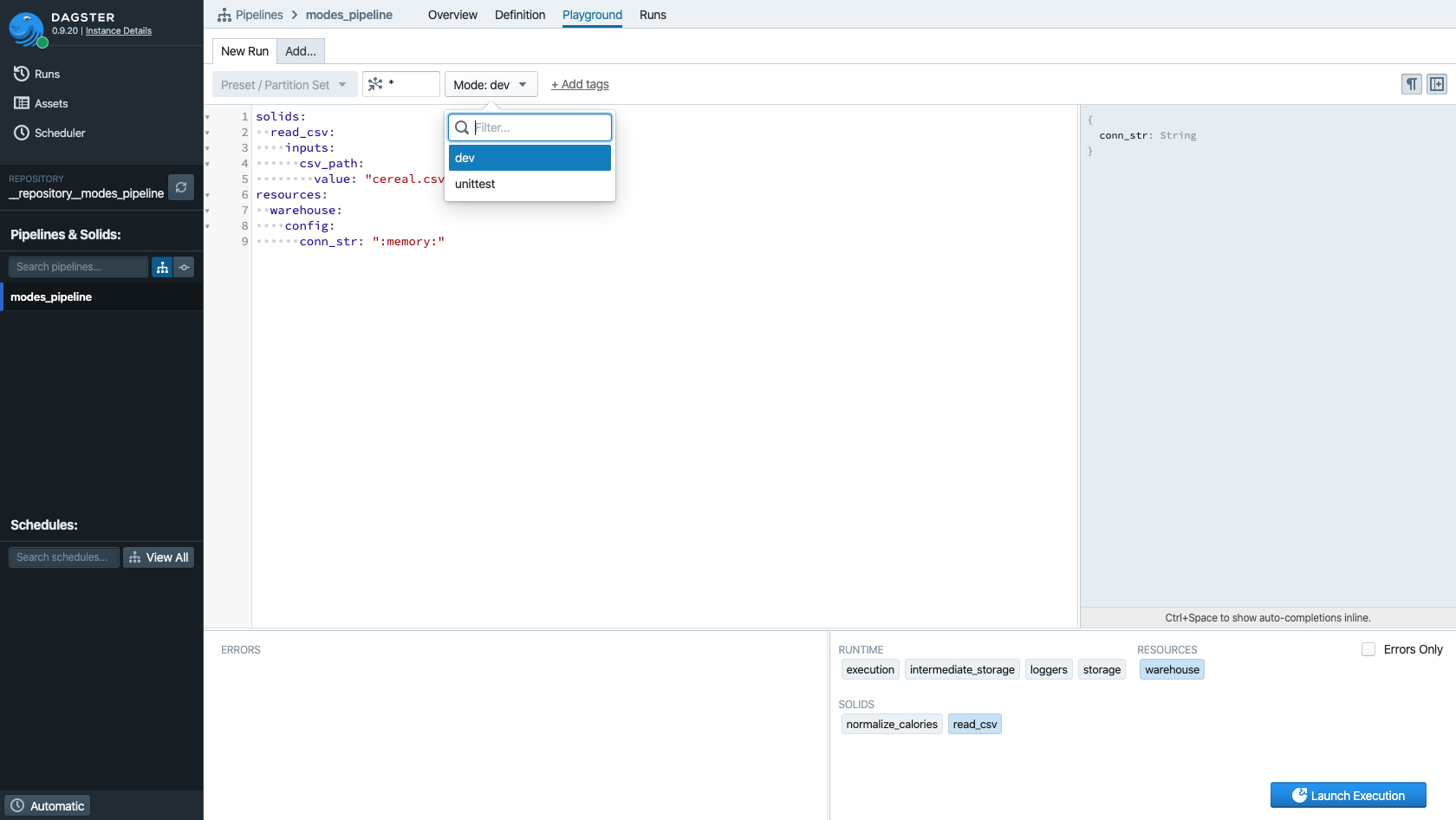
The config editor is Dagit is mode-aware, so when you switch modes and introduce a resource that requires additional config, the editor will prompt you.
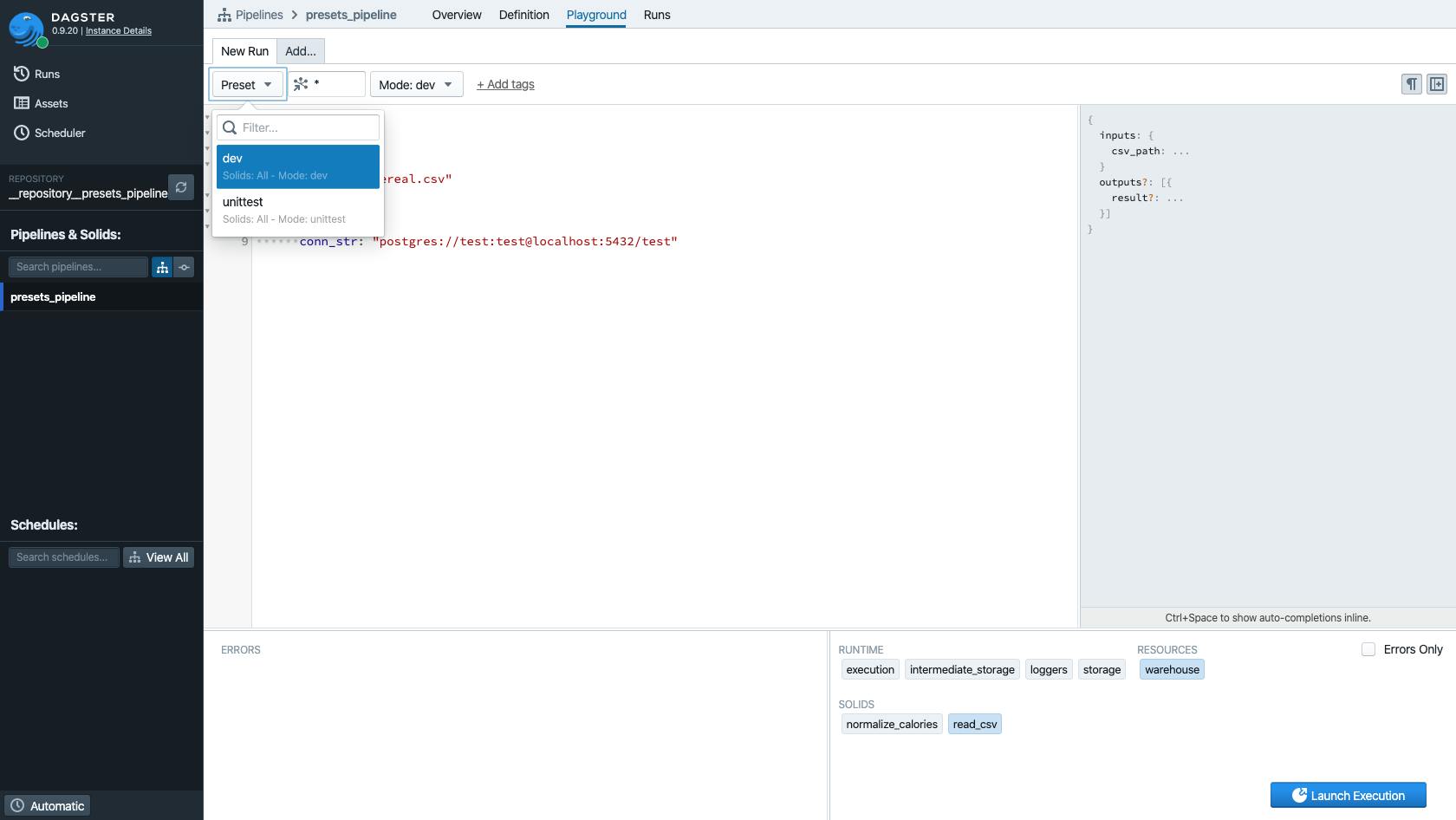
Pipeline Config Presets#
Useful as the Dagit config editor and the ability to stitch together YAML fragments is, once pipelines have been have been deployed and config is unlikely to change, it's often useful to distribute pipelines with embedded config. For example, you might point solids at different S3 buckets in different environments, or want to pull database credentials from different environment variables.
Dagster calls this a config preset:
@pipeline(
mode_defs=[
ModeDefinition(
name="unittest",
resource_defs={"warehouse": local_sqlite_warehouse_resource},
),
ModeDefinition(
name="dev",
resource_defs={
"warehouse": sqlalchemy_postgres_warehouse_resource
},
),
],
preset_defs=[
PresetDefinition(
"unittest",
run_config={
"solids": {
"read_csv": {
"inputs": {"csv_path": {"value": "cereal.csv"}}
}
},
"resources": {
"warehouse": {"config": {"conn_str": ":memory:"}}
},
},
mode="unittest",
),
PresetDefinition.from_files(
"dev",
config_files=[
file_relative_path(__file__, "presets_dev_warehouse.yaml"),
file_relative_path(__file__, "presets_csv.yaml"),
],
mode="dev",
),
],
)
def presets_pipeline():
normalize_calories(read_csv())
The config above illustrates two ways of defining a preset.
The first is to pass an run_config literal to the constructor. Because this dict is defined in
Python, you can do arbitrary computation to construct it—for instance, picking up environment
variables, making a call to a secrets store like Hashicorp Vault, etc.
The second is to use the from_files static constructor, and pass a list of file globs from which
to read YAML fragments. Order matters in this case, and keys from later files will overwrite keys
from earlier files.
To select a preset for execution, we can use the CLI, the Python API, or Dagit. From the CLI, use
-p or --preset:
dagster pipeline execute -f presets.py --preset unittest
From Python, you can use execute_pipeline
result = execute_pipeline(presets_pipeline, preset="unittest")
And in Dagit, we can use the "Presets" selector.