
IO Managers#
IO Managers are user-provided objects that store solid outputs and load them as inputs to downstream solids.
Relevant APIs#
| Name | Description |
|---|---|
@io_manager | A decorator used to define IO managers. |
IOManager | Base class for user-provided IO managers. |
Overview#
Dagster solids have inputs and outputs. When
a solid returns an output and a downstream solid takes that output as an input, where does the data
live in between? IOManagers let the user decide.
The IO manager APIs make it easy to separate code that's responsible for logical data transformation from code that's responsible for reading and writing the results. Solids can focus on business logic, while IO managers handle I/O. This separation makes it easier to test the business logic and run it in different environments.
Not all inputs depend on upstream outputs. The Unconnected Inputs overview
covers DagsterTypeLoaders and RootInputManagers (experimental), which let you decide how
inputs at the beginning of a pipeline are loaded.
Outputs and downstream inputs#
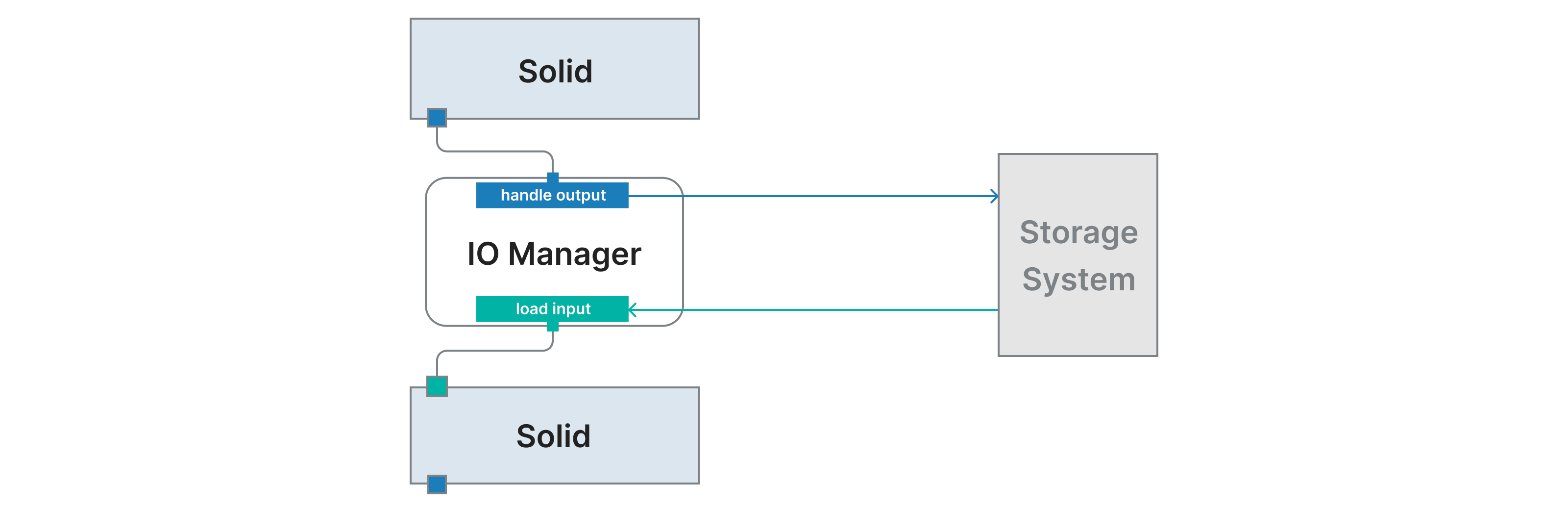
IOManagers are user-provided objects that are responsible for storing the output of a solid and loading it as input to downstream solids. For example, an IO Manager might store and load objects from files on a filesystem.Each solid output can have its own IOManager, or multiple solid outputs can share an IOManager. The IOManager that's used for handling a particular solid output is automatically used for loading it in downstream solids.
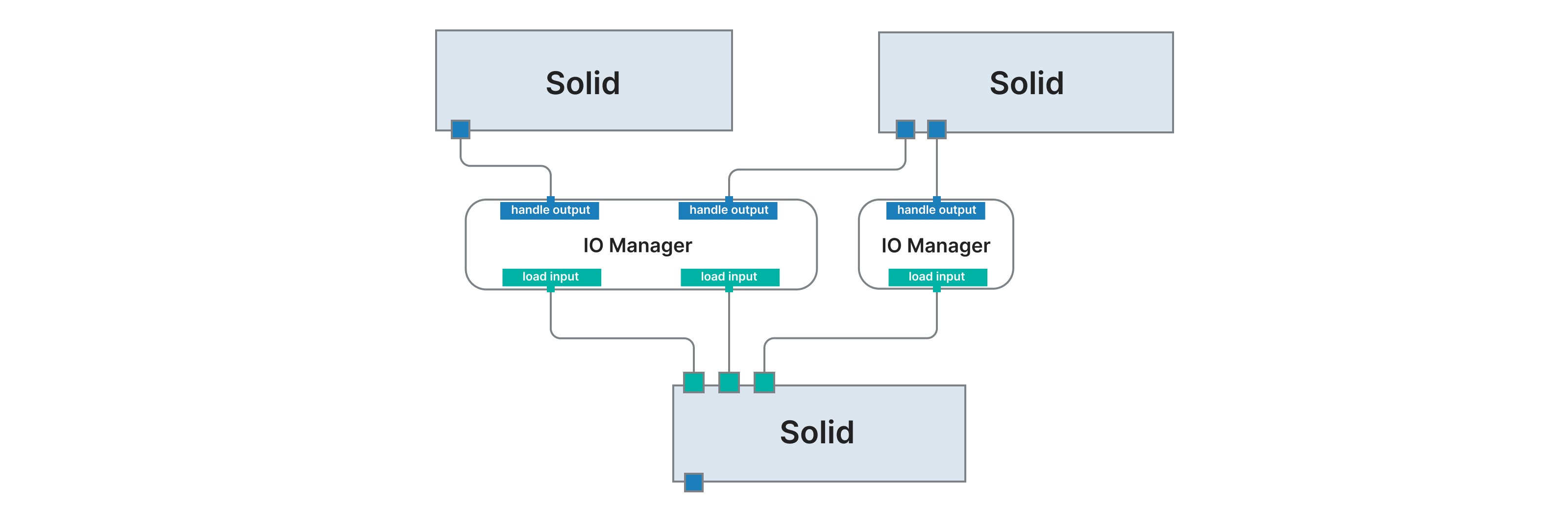
This diagram shows a pipeline with two IO managers, each of which is shared across a few inputs and outputs.
The default IOManager, mem_io_manager, stores outputs in
memory, but this only works for the single process executor. Dagster provides out-of-the-box
IOManagers that pickle objects and save them. These are fs_io_manager
, s3_pickle_io_manager
, adls2_pickle_io_manager
, or gcs_pickle_io_manager.
IOManagers are resources, which means users can supply different IOManagers for the same solid outputs in different situations. For example, you might use an in-memory IOManager for unit-testing a pipeline and an S3IOManager in production.
Using an IO manager#
Pipeline-wide IO manager#
By default, all the inputs and outputs in a pipeline use the same IOManager. This IOManager is
determined by the ResourceDefinition provided for the
"io_manager" resource key. "io_manager" is a resource key that Dagster reserves specifically
for this purpose.
Here’s how to specify that all solid outputs are stored using the fs_io_manager,
which pickles outputs and stores them on the local filesystem. It stores files in a directory with
the run ID in the path, so that outputs from prior runs will never be overwritten.
from dagster import ModeDefinition, fs_io_manager, pipeline, solid
@solid
def solid1(_):
return 1
@solid
def solid2(_, a):
return a + 1
@pipeline(mode_defs=[ModeDefinition(resource_defs={"io_manager": fs_io_manager})])
def my_pipeline():
solid2(solid1())
@pipeline(mode_defs=[ModeDefinition(resource_defs={"io_manager": fs_io_manager})])
def my_pipeline():
solid2(solid1())
Per-output IO manager#
Not all the outputs in a pipeline should necessarily be stored the same way. Maybe some of the outputs should live on the filesystem so they can be inspected, and others can be transiently stored in memory.
To select the IOManager for a particular output, you can set an io_manager_key on
the OutputDefinition, and then refer to that io_manager_key
when setting IO managers in your ModeDefinition. In this
example, the output of solid1 will go to fs_io_manager and the output of solid2 will go to mem_io_manager.
from dagster import ModeDefinition, OutputDefinition, fs_io_manager, mem_io_manager, pipeline, solid
@solid(output_defs=[OutputDefinition(io_manager_key="fs")])
def solid1(_):
return 1
@solid(output_defs=[OutputDefinition(io_manager_key="mem")])
def solid2(_, a):
return a + 1
@pipeline(mode_defs=[ModeDefinition(resource_defs={"fs": fs_io_manager, "mem": mem_io_manager})])
def my_pipeline():
solid2(solid1())
Defining an IO manager#
If you have specific requirements for where and how your outputs should be stored and retrieved, you can define your own IOManager. This boils down to implementing two functions: one that stores outputs and one that loads inputs.
To define an IO manager, use the @io_manager decorator.
class MyIOManager(IOManager):
def handle_output(self, context, obj):
write_csv("some/path")
def load_input(self, context):
return read_csv("some/path")
@io_manager
def my_io_manager(init_context):
return MyIOManager()
The io_manager decorator behaves nearly identically to
the resource decorator. It yields
an IOManagerDefinition, which is a subclass
of ResourceDefinition that will produce
an IOManager.
The provided context argument for handle_output is
an OutputContext. The provided context argument for
load_input is an InputContext. The linked API documentation
lists all the fields that are available on these objects.
Examples#
A custom IO manager that stores Pandas DataFrames in tables#
If your solids produce Pandas DataFrames that populate tables in a data warehouse, you might write something like the following. This IO manager uses the name assigned to the output as the name of the table to write the output to.
from dagster import IOManager, ModeDefinition, io_manager, pipeline
class DataframeTableIOManager(IOManager):
def handle_output(self, context, obj):
# name is the name given to the OutputDefinition that we're storing for
table_name = context.name
write_dataframe_to_table(name=table_name, dataframe=obj)
def load_input(self, context):
# upstream_output.name is the name given to the OutputDefinition that we're loading for
table_name = context.upstream_output.name
return read_dataframe_from_table(name=table_name)
@io_manager
def df_table_io_manager(_):
return DataframeTableIOManager()
@pipeline(mode_defs=[ModeDefinition(resource_defs={"io_manager": df_table_io_manager})])
def my_pipeline():
solid2(solid1())
Providing per-output config to an IO manager#
When launching a run, you might want to parameterize how particular outputs are stored.
For example, if your pipeline produces DataFrames to populate tables in a data warehouse, you might want to specify the table that each output goes to at run launch time.
To accomplish this, you can define an output_config_schema on the IO manager definition. The IOManager methods can access this config when storing or loading data, via the OutputContext.
class MyIOManager(IOManager):
def handle_output(self, context, obj):
table_name = context.config["table"]
write_dataframe_to_table(name=table_name, dataframe=obj)
def load_input(self, context):
table_name = context.upstream_output.config["table"]
return read_dataframe_from_table(name=table_name)
@io_manager(output_config_schema={"table": str})
def my_io_manager(_):
return MyIOManager()
Then, when executing a pipeline, you can pass in this per-output config.
@pipeline(mode_defs=[ModeDefinition(resource_defs={"io_manager": my_io_manager})])
def my_pipeline():
solid2(solid1())
execute_pipeline(
my_pipeline,
run_config={
"solids": {
"solid1": {"outputs": {"result": {"table": "table1"}}},
"solid2": {"outputs": {"result": {"table": "table2"}}},
}
},
)
Providing per-output metadata to an IO manager (experimental)#
You might want to provide static metadata that controls how particular outputs are stored. You don't plan to change the metadata at runtime, so it makes more sense to attach it to a definition rather than expose it as a configuration option.
For example, if your pipeline produces DataFrames to populate tables in a data warehouse, you might want to specify that each output always goes to a particular table. To accomplish this, you can define metadata on each OutputDefinition:
@solid(output_defs=[OutputDefinition(metadata={"schema": "some_schema", "table": "some_table"})])
def solid1(_):
"""Return a Pandas DataFrame"""
@solid(output_defs=[OutputDefinition(metadata={"schema": "other_schema", "table": "other_table"})])
def solid2(_, _input_dataframe):
"""Return a Pandas DataFrame"""
@solid(output_defs=[OutputDefinition(metadata={"schema": "some_schema", "table": "some_table"})])
def solid1(_):
"""Return a Pandas DataFrame"""
@solid(output_defs=[OutputDefinition(metadata={"schema": "other_schema", "table": "other_table"})])
def solid2(_, _input_dataframe):
"""Return a Pandas DataFrame"""
The IOManager can then access this metadata when storing or retrieving data, via the OutputContext.
In this case, the table names are encoded in the pipeline definition. If, instead, you want to be able to set them at run time, the next section describes how.
class MyIOManager(IOManager):
def handle_output(self, context, obj):
table_name = context.metadata["table"]
schema = context.metadata["schema"]
write_dataframe_to_table(name=table_name, schema=schema, dataframe=obj)
def load_input(self, context):
table_name = context.upstream_output.metadata["table"]
schema = context.upstream_output.metadata["schema"]
return read_dataframe_from_table(name=table_name, schema=schema)
@io_manager
def my_io_manager(_):
return MyIOManager()
Testing an IO manager#
The easiest way to test an IO manager is to construct an OutputContext
or InputContext and pass it to the handle_output or
load_input method of the IO manager.
Here's an example for a simple IO manager that stores outputs in an in-memory dictionary that's keyed on the step and name of the output.
from dagster import IOManager, InputContext, OutputContext
class MyIOManager(IOManager):
def __init__(self):
self.storage_dict = {}
def handle_output(self, context, obj):
self.storage_dict[(context.step_key, context.name)] = obj
def load_input(self, context):
return self.storage_dict[(context.upstream_output.step_key, context.upstream_output.name)]
def test_my_io_manager_handle_output():
my_io_manager = MyIOManager()
context = OutputContext(name="abc", step_key="123")
my_io_manager.handle_output(context, 5)
assert my_io_manager.storage_dict[("123", "abc")] == 5
def test_my_io_manager_load_input():
my_io_manager = MyIOManager()
my_io_manager.storage_dict[("123", "abc")] = 5
context = InputContext(upstream_output=OutputContext(name="abc", step_key="123"))
assert my_io_manager.load_input(context) == 5